Go Data Structures
Russ Cox
November 24, 2009
research.swtch.com/godata
Posted on Tuesday, November 24, 2009.
November 24, 2009
research.swtch.com/godata
When explaining Go to new programmers, I've found that it often helps to explain what Go values look like in memory, to build the right intuition about which operations are expensive and which are not. This post is about basic types, structs, arrays, and slices.
Basic types
Let's start with some simple examples:

The variable i has type int, represented in memory as a single 32-bit word. (All these pictures show a 32-bit memory layout; in the current implementations, only the pointer gets bigger on a 64-bit machine—int is still 32 bits—though an implementation could choose to use 64 bits instead.)
The variable j has type int32, because of the explicit conversion. Even though i and j have the same memory layout, they have different types: the assignment i = j is a type error and must be written with an explicit conversion: i = int(j).
The variable f has type float, which the current implementations represent as a 32-bit floating-point value. It has the same memory footprint as the int32 but a different internal layout.
Structs and pointers
Now things start to pick up. The variable bytes has type [5]byte, an array of 5 bytes. Its memory representation is just those 5 bytes, one after the other, like a C array. Similarly, primes is an array of 4 ints.
Go, like C but unlike Java, gives the programmer control over what is and is not a pointer. For example, this type definition:
type Point struct { X, Y int }
defines a simple struct type named Point, represented as two adjacent ints in memory.

The composite literal syntax Point{10, 20} denotes an initialized Point. Taking the address of a composite literal denotes a pointer to a freshly allocated and initialized Point. The former is two words in memory; the latter is a pointer to two words in memory.
Fields in a struct are laid out side by side in memory.
type Rect1 struct { Min, Max Point }
type Rect2 struct { Min, Max *Point }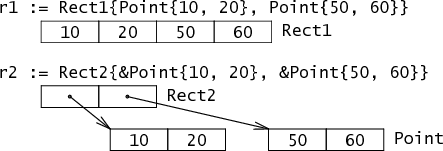
Rect1, a struct with two Point fields, is represented by two Points—four ints—in a row. Rect2, a struct with two *Point fields, is represented by two *Points.
Programmers who have used C probably won't be surprised by the distinction between Point fields and *Point fields, while programmers who have only used Java or Python (or ...) may be surprised by having to make the decision. By giving the programmer control over basic memory layout, Go provides the ability to control the total size of a given collection of data structures, the number of allocations, and the memory access patterns, all of which are important for building systems that perform well.
Strings
With those preliminaries, we can move on to more interesting data types.

(The gray arrows denote pointers that are present in the implementation but not directly visible in programs.)
A string is represented in memory as a 2-word structure containing a pointer to the string data and a length. Because the string is immutable, it is safe for multiple strings to share the same storage, so slicing s results in a new 2-word structure with a potentially different pointer and length that still refers to the same byte sequence. This means that slicing can be done without allocation or copying, making string slices as efficient as passing around explicit indexes.
(As an aside, there is a well-known gotcha in Java and other languages that when you slice a string to save a small piece, the reference to the original keeps the entire original string in memory even though only a small amount is still needed. Go has this gotcha too. The alternative, which we tried and rejected, is to make string slicing so expensive—an allocation and a copy—that most programs avoid it.)
Slices
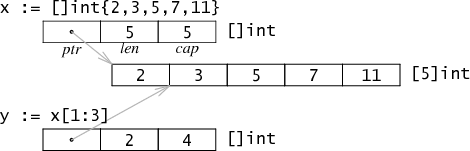
A slice is a reference to a section of an array. In memory, it is a 3-word structure contaning a pointer to the first element, the length of the slice, and the capacity. The length is the upper bound for indexing operations like x[i] while the capacity is the upper bound for slice operations like x[i:j].
Like slicing a string, slicing an array does not make a copy: it only creates a new structure holding a different pointer, length, and capacity. In the example, evaluating the composite literal []int{2, 3, 5, 7, 11} creates a new array containing the five values and then sets the fields of the slice x to describe that array. The slice expression x[1:3] does not allocate more data: it just writes the fields of a new slice structure to refer to the same backing store. In the example, the length is 2—y[0] and y[1] are the only valid indexes—but the capacity is 4—y[0:4] is a valid slice expression. (See Effective Go for more about length and capacity and how slices are used.)
Because slices are multiword structures, not pointers, the slicing operation does not need to allocate memory, not even for the slice header, which can usually be kept on the stack. This representation makes slices about as cheap to use as passing around explicit pointer and length pairs in C. Go originally represented a slice as a pointer to the structure shown above, but doing so meant that every slice operation allocated a new memory object. Even with a fast allocator, that creates a lot of unnecessary work for the garbage collector, and we found that, as was the case with strings above, programs avoided slicing operations in favor of passing explicit indices. Removing the indirection and the allocation made slices cheap enough to avoid passing explicit indices in most cases.
New and Make
Go has two data structure creation functions: new and make. The distinction is a common early point of confusion but seems to quickly become natural. The basic distinction is that new(T) returns a *T, a pointer that Go programs can dereference implicitly (the black pointers in the diagrams), while make(T, args) returns an ordinary T, not a pointer. Often that T has inside it some implicit pointers (the gray pointers in the diagrams). New returns a pointer to zeroed memory, while make returns a complex structure.

There is a way to unify these two, but it would be a significant break from the C and C++ tradition: define make(*T) to return a pointer to a newly allocated T, so that the current new(Point) would be written make(*Point). We tried this for a few days but decided it was too different from what people expected of an allocation function.
Coming soon...
This has already gotten a bit long. Interface values, maps, and channels will have to wait for future posts.
(Comments originally posted via Blogger.)
tivadj (November 24, 2009 12:57 PM) So what about Go performance comparing to something from C,C++; Java or C#? Expected degrade about -5% ?
Dubhead (November 24, 2009 6:22 PM) Thank you for the article, it re-arranged my understanding of the topic.
Two possible corrections:
In 'Slices', 'x[0:4] is a valid slice expression' should be something like 'if y:=x[1:3], then y[0:4] is valid slice expression'.
In 'new and make' diagram, new(Rect) should be new(Rect1).
Artyom Shalkhakov (November 24, 2009 7:28 PM) You've shown that types in Go prescribe memory layout of data.
I wonder whether it's possible to describe certain invariants using the type system of Go?
tav (November 24, 2009 7:49 PM) This post has been removed by the author.
tav (November 24, 2009 7:51 PM) Hey Russ,
Thanks for such an informative article. As a Python coder coming to Go, I was wondering if you would consider a series of "best Go patterns" for future articles?
I — and probably a good number of others — are fairly clueless when it comes to issues of memory allocation, optimisation, etc. So it would be super helpful to learn better ways of doing things by way of comparison of "good" and "bad" ways of solving the same problem in Go…
In any case, I look forward to your follow-up post on maps, interfaces and channels. Thanks!
-- tav@espians.com
Julian Morrison (November 25, 2009 2:07 AM) What is the utility of disallowing an index beyond the slice, but allowing a new slice up to the capacity? Is it to give something approximating the fill pointer of Java's Buffer interface?
Russ Cox (November 29, 2009 10:07 PM) @tivadj: That's certainly the goal. You can look at the shootout site to see real comparisons. Note that what passes for C or C++ in those benchmarks typically has liberal amounts of asm sprinkled in.
@Dubhead: Thanks; fixed.
@Artyom: What kinds of invariants are you wondering about?
@tav: There's already a document that tries to do that: http://golang.org/doc/effective_go.html.
@Julian: see the slices section of http://golang.org/doc/effective_go.html.
It helps catch out-of-bounds errors to disallow
indexing past len, because in most usage, the
data past len does not contain anything useful.
Artyom Shalkhakov (December 3, 2009 11:35 PM) @rsc: For instance, I'd like my compiler to check an array out-of-bounds access for me. There are research prototypes (e.g., ATS), but it would be great to get this one in a practical programming language. :)
MikeZ (December 5, 2009 7:00 AM) A question about garbage collection of strings. Let's say we have a string and a slice of it:
s := "hello" // ptr to "hello"
t := s[2:2] // ptr to "llo"
s = "goodbye" // "hello" now garbage?
What happens to t if the current garbage collector collects after the last assignment to s? Is the current GC smart enough to recognize that t points to the interior of "hello", so "hello" should not be collected?
Brian Bulkowski (December 6, 2009 4:06 PM) I believe the 'shootout' site is a poor measure for what I use languages for. I expect to use strings, hashes, and lists liberally; those tests avoid those structures and concentrate on loops and read and write.
That having been said, shootout claims Go is on the same level as Erlang, and nowhere near C.
I looked at a few of the C programs; none included asm() statements. The binary tree functionality is 20x slower in Go than C.
I'm willing to believe that Go is immature and needs work, but to hear people claim "go is meeting its goals" when it's 20x slower than C (instead of 20 percent slower) steams me.
Russ Cox (December 6, 2009 4:51 PM) @Brian:
The binary tree shootout is not a binary tree benchmark. It's a garbage collection benchmark, and Go's garbage collector is pretty slow. On the other hand, it has one, unlike C, and it will get better.
If you look at real computation, instead of libraries, Go is holding its own with equivalent C code. reverse-complement is now pretty much tied with the equivalent C program (not yet on the site, but in the Go repository), mandelbrot is 10% slower, nbody is 50% slower only because it doesn't inline the call to sqrt.
Also, who said Go was meeting its performance goas? I think it's doing pretty well for a rough implementation, but there is plenty of room for improvement and lots of low-hanging fruit.
Greg (April 4, 2011 11:19 PM) really excellent description, thanks Russ.