Using Uninitialized Memory for Fun and Profit
Russ Cox
March 14, 2008
research.swtch.com/sparse
Posted on Friday, March 14, 2008.
March 14, 2008
research.swtch.com/sparse
This is the story of a clever trick that's been around for at least 35 years, in which array values can be left uninitialized and then read during normal operations, yet the code behaves correctly no matter what garbage is sitting in the array. Like the best programming tricks, this one is the right tool for the job in certain situations. The sleaziness of uninitialized data access is offset by performance improvements: some important operations change from linear to constant time.
Alfred Aho, John Hopcroft, and Jeffrey Ullman's 1974 book The Design and Analysis of Computer Algorithms hints at the trick in an exercise (Chapter 2, exercise 2.12):
Develop a technique to initialize an entry of a matrix to zero the first time it is accessed, thereby eliminating the O(||V||2) time to initialize an adjacency matrix.
Jon Bentley's 1986 book Programming Pearls expands on the exercise (Column 1, exercise 8; exercise 9 in the Second Edition):
One problem with trading more space for less time is that initializing the space can itself take a great deal of time. Show how to circumvent this problem by designing a technique to initialize an entry of a vector to zero the first time it is accessed. Your scheme should use constant time for initialization and each vector access; you may use extra space proportional to the size of the vector. Because this method reduces initialization time by using even more space, it should be considered only when space is cheap, time is dear, and the vector is sparse.
Aho, Hopcroft, and Ullman's exercise talks about a matrix and Bentley's exercise talks about a vector, but for now let's consider just a simple set of integers.
One popular representation of a set of n integers ranging from 0 to m is a bit vector, with 1 bits at the positions corresponding to the integers in the set. Adding a new integer to the set, removing an integer from the set, and checking whether a particular integer is in the set are all very fast constant-time operations (just a few bit operations each). Unfortunately, two important operations are slow: iterating over all the elements in the set takes time O(m), as does clearing the set. If the common case is that m is much larger than n (that is, the set is only sparsely populated) and iterating or clearing the set happens frequently, then it could be better to use a representation that makes those operations more efficient. That's where the trick comes in.
Preston Briggs and Linda Torczon's 1993 paper,
“An Efficient Representation for Sparse Sets,”
describes the trick in detail.
Their solution represents the sparse set using an integer
array named dense and an integer n
that counts the number of elements in dense.
The dense array is simply a packed list of the elements in the
set, stored in order of insertion.
If the set contains the elements 5, 1, and 4, then n = 3 and
dense[0] = 5, dense[1] = 1, dense[2] = 4:
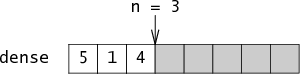
Together n and dense are
enough information to reconstruct the set, but this representation
is not very fast.
To make it fast, Briggs and Torczon
add a second array named sparse
which maps integers to their indices in dense.
Continuing the example,
sparse[5] = 0, sparse[1] = 1,
sparse[4] = 2.
Essentially, the set is a pair of arrays that point at
each other:
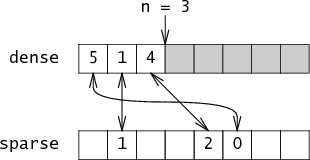
Adding a member to the set requires updating both of these arrays:
add-member(i): dense[n] = i sparse[i] = n n++
It's not as efficient as flipping a bit in a bit vector, but it's still very fast and constant time.
To check whether i is in the set, you verify that
the two arrays point at each other for that element:
is-member(i): return sparse[i] < n && dense[sparse[i]] == i
If i is not in the set, then it doesn't matter what sparse[i] is set to:
either sparse[i]
will be bigger than n or it will point at a value in
dense that doesn't point back at it.
Either way, we're not fooled. For example, suppose sparse
actually looks like:
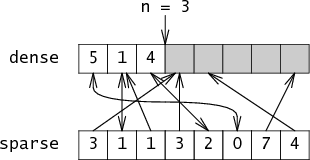
Is-member knows to ignore
members of sparse that point past n or that
point at cells in dense that don't point back,
ignoring the grayed out entries:
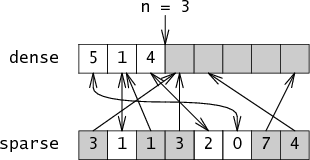
Notice what just happened:
sparse can have any arbitrary values in
the positions for integers not in the set,
those values actually get used during membership
tests, and yet the membership test behaves correctly!
(This would drive valgrind nuts.)
Clearing the set can be done in constant time:
clear-set(): n = 0
Zeroing n effectively clears
dense (the code only ever accesses
entries in dense with indices less than n), and
sparse can be uninitialized, so there's no
need to clear out the old values.
This sparse set representation has one more trick up its sleeve:
the dense array allows an
efficient implementation of set iteration.
iterate(): for(i=0; i<n; i++) yield dense[i]
Let's compare the run times of a bit vector implementation against the sparse set:
| Operation | Bit Vector | Sparse set | ||
| is-member | O(1) | O(1) | ||
| add-member | O(1) | O(1) | ||
| clear-set | O(m) | O(1) | ||
| iterate | O(m) | O(n) |
The sparse set is as fast or faster than bit vectors for every operation. The only problem is the space cost: two words replace each bit. Still, there are times when the speed differences are enough to balance the added memory cost. Briggs and Torczon point out that liveness sets used during register allocation inside a compiler are usually small and are cleared very frequently, making sparse sets the representation of choice.
Another situation where sparse sets are the better choice is work queue-based graph traversal algorithms. Iteration over sparse sets visits elements in the order they were inserted (above, 5, 1, 4), so that new entries inserted during the iteration will be visited later in the same iteration. In contrast, iteration over bit vectors visits elements in integer order (1, 4, 5), so that new elements inserted during traversal might be missed, requiring repeated iterations.
Returning to the original exercises, it is trivial to change
the set into a vector (or matrix) by making dense
an array of index-value pairs instead of just indices.
Alternately, one might add the value to the sparse
array or to a new array.
The relative space overhead isn't as bad if you would have been
storing values anyway.
Briggs and Torczon's paper implements additional set operations and examines performance speedups from using sparse sets inside a real compiler.
(Comments originally posted via Blogger.)
valhallasw (March 14, 2008 12:58 PM) is-member(i):
return sparse[i] < n && dense[sparse[i]]
Shouldn't this be
return sparse[i] < n && dense[sparse[i]]==i
, as dense can contain null elements. Obviously this only fails with a false=0 representation.
Russ Cox (March 14, 2008 1:50 PM) @valhallasw: It already said
dense[sparse[i]] = i; I've changed = to == so the pseudo-code is more like C.
valhallasw (March 14, 2008 3:13 PM) Doh. The pre-block cuts of anything that comes too far to the right, so the ==i didn't show up. Never knew pre-blocks within a div could be this evil :)
Russ Cox (March 14, 2008 3:43 PM) @valhallasw: Thanks for pointing that out. Added some CSS magic to make the pre-blocks wrap.
drew (March 14, 2008 3:46 PM) There's also constant time remove (though a little more work):
remove-member(i):
if not is-member(i): return
j = dense[n-1];
dense[sparse[i]] = j;
sparse[j] = sparse[i];
n = n - 1
gruseom (March 15, 2008 12:17 AM) Very cool. But is it correct to say that the space requirement is two words per element (by which I assume you mean 2*n)? What if one of the integers in the set is very large, wouldn't the sparse vector have to consume correspondingly large space?
Russ Cox (March 15, 2008 11:06 AM) @gruseom: The space cost is 2 words per potential entry (per universe member). I've changed the wording to be clearer, I hope. The contrast there is just supposed to be the 2 words vs 1 bit.
Dan (March 15, 2008 9:30 PM) Took a look at this from a security perspective, since at first glance, I thought I was looking at another instance of someone thinking uninitialized RAM contains random data. Actually, this works, and is pretty cool! Here's how it looks, from another lens. The canonical, trusted "array" is the dense array. However, this is potentially slow to access. So, a second array is created, in which the value in the array is itself used as an index into the dense array. Now, the uninitialized memory could contain anything, but the value there will either refer back to the entry in the trusted dataset, or it will not.
One possible source of trouble is the fact that if the same i is added to the array twice, the second entry will blow away the first one in the sparse set, meaning you'll have a value in the dense set with no index entry pointing back to it. For certain scenarios, this could be a problem.
A much bigger issue, however, is that the integer isn't called out as needing to be unsigned :) If it isn't, the memory at sparse[i] could contain a number greater than MAXINT, which would be less than 0, and thus pass n<0 membership. Your system would (likely) crash.
Dan (March 15, 2008 10:28 PM) Besides crashing, in the case where sparse[i] is less than 0, then dense[sparse[i]] is also uninitialized memory. So, if dense[sparse[i]] happens to contain i, then you'll get a false positive for set membership.
(And, of course, I assume that i is constrained to be less than the size of the region malloc'd to sparse)
Dan (March 15, 2008 10:29 PM) drew,
Check that n>0 :)
Timothy Barrington-Smythe (March 15, 2008 10:33 PM) 10 print "my brain hurts"
20 goto 10
splag (March 15, 2008 10:44 PM) Hey Russ,
Came across this blog through a random link. Then I was like... hey, I know this guy!
Great blog. I've bookmarked it. Hope you're doing well.
AJ
Russ Cox (March 16, 2008 5:04 AM) @dan: Yes: i is unsigned, and in general add-member needs to check whether the number is already there and all the routines should check i against the size of sparse.
I was trying to keep the presentation simple. The paper has all the gory details.
datatype (March 16, 2008 7:30 AM) Very cool. I will use this some day.
Mobius (March 16, 2008 9:27 AM) Don't the elements of dense[] have to be unique integers for this to work? I
Russ Cox (March 16, 2008 9:39 AM) @mobius: Yes. But a set is a data structure that only stores each element once, so that's okay. Or if you adapt it to do what the exercises asked, dense contains the list of vector indices that have been initialized with data. Either way, it's not a real restriction that the elements of dense be unique.
Dan (March 16, 2008 11:51 AM) @rsc i can be unsigned all day -- it's n that must be unsigned :) The problem is when you dereference sparse[i]. If that value happens to be greater than MAXINT, it'll miss your n<0 check and Read AV.
I think it's a reasonable presumption that i will be generated in such a manner that it will fit into sparse[]. But you're making a post about how you can handle arbitrary values in memory -- you fail on half the values right now :)
Dan (March 16, 2008 8:46 PM) Actually, I'm wrong. It's the declaration for elements in sparse[] that must be unsigned. Bah.
Rklz2 (April 7, 2008 11:40 PM) At first I thought it's going to be a virtual memory trick. But no.
Well, actually, it could be. This reminds me of copying garbage collectors which also trade more space usage for less time allocating, and the algorithms when stripped of all the complexity have the same gist as those in the article.
DAGwyn (May 19, 2010 3:21 AM) Note that all of sparse[] must be explicitly initialized (to what doesn't matter, might as well be 0) to ensure that a trap representation is not accessed. Most people don't encounter platforms where that is an issue, but it is a possibility allowed by the C standard.
hasknewbie (July 11, 2010 12:32 PM) A lot of these indexing tricks
were discovered by Cray programmers
that used the Cray scatter/gather instructions. You could for example determine if a set of integers were unique by writing out an iota to a vector (1...n) then use the set as indexes to scatter and then read the result using the set as indexes to gather. If the results where the same 1..n then the set was unique.
Zooko (July 12, 2010 7:50 AM) The CPython memory manager does this, and it does indeed drive valgrind nuts. But fortunately valgrind has a nice feature for suppressing warnings and CPython's valgrind suppressions file suppresses those ones.
Russ Cox (January 6, 2011 10:12 AM) Now that RE2 is open source I can point to this overengineered C++ implementation:
util/sparse_array.h
util/sparse_set.h
One example of the graph algorithms I mentioned at the end is the NFA simulation work lists.
re2/nfa.cc
Anonymous (January 14, 2011 9:32 AM) While this may have been true in the past, the Consumption of Cache lines on current hardware will make a bit vector outperform this method on anything but very small sets of data.
Russ Cox (January 14, 2011 10:11 AM) @anonymous: It all depends on how often you clear the set and start over. If reset is rare, then sure. If reset is common, though, you're looking at O(1) vs O(n). As n gets large, that catches up with you no matter what you think of the memory system.
Jean-Denis (February 22, 2011 1:53 AM) The linked paper doesn't seem to be available any more, except perhaps behind pay walls. Could anybody provide a working link, or possibly email it to me?
Thanks,
jdmuys at gmail dot com
Layla (March 4, 2011 9:42 PM) Hi,
Cool Post! This is a neat trick, which I've used in the past, and the benefits for walking the set are really great (For many problems, they're far more important than the benefit of not needing to initialize the array!) But I feel I should defend Bit Vectors a little bit, since I think they're getting a bit of a bad rap on the clearing issue :-)
Bit Vectors don't have to be O(M) to clear - they can easily be O(M/W) or O(M/(W*IPC)) where W is the Bit Width of your architecture, and IPC is the number of instructions per clock cycle.
On a single-issue 64-bit architecture, this would be O(M/64)... on a dual-issue 128-bit SIMD architecture (like Bulldozer), this could be O(M/256).
O(M/64) and O(M/256) still aren't O(1) for set-sizes larger than 64 and 256, respectively, but O(M/W*IPC) is still generally a lot more friendly than O(M)! :)
Anonymous (December 7, 2011 3:44 PM) @Layla
That presumes that the CPU can issue analogous memory operations to clear those words. You have to take the memory bus into account. Can an x64 CPU clear 256-bits with a single instruction over the bus?